In this example we will use a sparse binary regression with hierarchies on the scale of the independent variable’s parameters that function as a proxy for variable selection. We will use the Horseshoe prior to Carvalho et al., 2010 to ensure sparsity.
The Horseshoe prior consists in putting a prior on the scale of the regression parameter : the product of a global and local parameter that are both concentrated at 0, thus allowing the corresponding regression parameter to degenerate at 0 and effectively excluding this parameter from the model. This kind of model is challenging for samplers: the prior on ’s scale parameter creates funnel geometries that are hard to efficiently explore Papaspiliopoulos et al., 2007.
Mathematically, we will consider the following model:
The model is run on its non-centered parametrization Papaspiliopoulos et al., 2007 with data from the numerical version of the German credit dataset. The target posterior is defined by its likelihood. We implement the model in pure JAX:
Notebook Cell
import matplotlib.pyplot as plt
plt.rcParams["axes.spines.right"] = False
plt.rcParams["axes.spines.top"] = Falseimport jax
from datetime import date
rng_key = jax.random.key(int(date.today().strftime("%Y%m%d")))German credit dataset¶
We will use the sparse regression model on the German credit dataset Dua & Graff, 2017. We use the numeric version that is adapted to models that cannot handle categorical data:
import pandas as pd
data = pd.read_table(
"https://archive.ics.uci.edu/ml/machine-learning-databases/statlog/german/german.data-numeric",
header=None,
sep=r"\s+",
)Each row in the dataset corresponds to a different customer. The dependent variable is equal to 1 when the customer has good credit and 2 when it has bad credit; we encode it so a customer with good credit corresponds to 1, a customer with bad credit 1:
y = -1 * (data.iloc[:, -1].values - 2)r_bad = len(y[y==0.]) / len(y)
r_good = len(y[y>1]) / len(y)
print(f"{r_bad*100}% of the customers in the dataset are classified as having bad credit.")30.0% of the customers in the dataset are classified as having bad credit.
The regressors are defined on different scales so we normalize their values, and add a column of 1 that corresponds to the intercept:
import numpy as np
X = (
data.iloc[:, :-1]
.apply(lambda x: -1 + (x - x.min()) * 2 / (x.max() - x.min()), axis=0)
.values
)
X = np.concatenate([np.ones((1000, 1)), X], axis=1)Models¶
We define the log-density function in pure JAX. We work in log-transformed coordinates for and so the sampler can operate on variables defined on the real line, and include the corresponding log-Jacobian correction terms:
import jax.numpy as jnp
import jax.scipy.stats as stats
def logdensity_fn(x):
log_tau = x['log_tau']
log_lmbda = x['log_lmbda']
beta = x['beta']
tau = jnp.exp(log_tau)
lmbda = jnp.exp(log_lmbda)
# HalfCauchy(0, 1) log-density in log-space (includes log-Jacobian of exp transform)
log_p_tau = jnp.log(2.0 / jnp.pi) - jnp.log1p(tau ** 2) + log_tau
log_p_lmbda = jnp.sum(jnp.log(2.0 / jnp.pi) - jnp.log1p(lmbda ** 2) + log_lmbda)
# beta ~ Normal(0, tau * lambda)
log_p_beta = jnp.sum(stats.norm.logpdf(beta, loc=0.0, scale=tau * lmbda))
# y ~ Bernoulli(sigmoid(-X @ beta))
eta = X @ beta
log_likelihood = jnp.sum(
y * jax.nn.log_sigmoid(-eta) + (1 - y) * jax.nn.log_sigmoid(eta)
)
return log_p_tau + log_p_lmbda + log_p_beta + log_likelihoodLet us now define a utility function that builds a sampling loop:
def inference_loop(rng_key, init_state, kernel, n_iter):
keys = jax.random.split(rng_key, n_iter)
def step(state, key):
state, info = kernel(key, state)
return state, (state, info)
_, (states, info) = jax.lax.scan(step, init_state, keys)
return states, infoMEADS¶
The MEADS algorithm Hoffman & Sountsov, 2022 is a combination of Generalized HMC with a parameter tuning procedure. Let us initialize the position of the chain first:
num_chains = 128
num_warmup = 2000
num_samples = 2000
rng_key, key_b, key_l, key_t = jax.random.split(rng_key, 4)
init_position = {
"beta": jax.random.normal(key_b, (num_chains, X.shape[1])),
"log_lmbda": jax.random.normal(key_l, (num_chains, X.shape[1])),
"log_tau": jax.random.normal(key_t, (num_chains,)),
}Here we will not use the adaptive version of the MEADS algorithm, but instead use their heuristics as an adaptation procedure for Generalized Hamiltonian Monte Carlo kernels:
import blackjax
rng_key, key_warmup, key_sample = jax.random.split(rng_key, 3)
meads = blackjax.meads_adaptation(logdensity_fn, num_chains)
(state, parameters), _ = meads.run(key_warmup, init_position, num_warmup)
kernel = blackjax.ghmc(logdensity_fn, **parameters).step
# Choose the last state of the first k chains as a starting point for the sampler
n_parallel_chains = 4
init_states = jax.tree.map(lambda x: x[:n_parallel_chains], state)
keys = jax.random.split(key_sample, n_parallel_chains)
samples, info = jax.vmap(inference_loop, in_axes=(0, 0, None, None))(
keys, init_states, kernel, num_samples
)Let us look a high-level summary statistics for the inference, including the split-Rhat value and the number of effective samples:
from numpyro.diagnostics import print_summary
print_summary(samples.position)
mean std median 5.0% 95.0% n_eff r_hat
beta[0] -0.15 0.28 -0.08 -0.61 0.25 10.85 1.13
beta[1] -0.83 0.11 -0.83 -1.00 -0.64 74.23 1.04
beta[2] 1.24 0.28 1.25 0.79 1.68 79.15 1.04
beta[3] -0.69 0.18 -0.69 -1.03 -0.39 65.44 1.02
beta[4] 0.24 0.29 0.17 -0.14 0.76 75.38 1.05
beta[5] -0.39 0.11 -0.39 -0.57 -0.19 116.14 1.03
beta[6] -0.21 0.15 -0.21 -0.45 0.02 85.18 1.04
beta[7] -0.22 0.17 -0.21 -0.50 0.03 92.52 1.03
beta[8] -0.01 0.09 -0.01 -0.16 0.12 85.26 1.03
beta[9] 0.21 0.14 0.21 -0.01 0.42 117.12 1.04
beta[10] -0.15 0.19 -0.10 -0.49 0.11 71.44 1.05
beta[11] -0.26 0.11 -0.26 -0.44 -0.07 96.23 1.05
beta[12] 0.18 0.19 0.16 -0.08 0.50 96.73 1.04
beta[13] 0.01 0.08 0.01 -0.15 0.14 34.42 1.07
beta[14] -0.07 0.08 -0.05 -0.19 0.05 110.80 1.02
beta[15] -0.31 0.25 -0.28 -0.71 0.04 55.01 1.07
beta[16] 0.29 0.09 0.30 0.15 0.44 171.62 1.03
beta[17] -0.35 0.18 -0.34 -0.60 -0.01 63.10 1.05
beta[18] 0.26 0.18 0.25 -0.03 0.52 57.02 1.03
beta[19] 0.35 0.25 0.34 -0.03 0.73 74.83 1.02
beta[20] 0.14 0.13 0.13 -0.08 0.33 80.39 1.05
beta[21] -0.06 0.10 -0.04 -0.24 0.09 106.34 1.03
beta[22] -0.02 0.13 -0.01 -0.25 0.19 103.43 1.04
beta[23] -0.00 0.07 0.00 -0.14 0.11 151.83 1.03
beta[24] 0.00 0.07 -0.00 -0.11 0.12 141.46 1.04
log_lmbda[0] -0.30 0.99 -0.31 -1.92 1.40 102.97 1.03
log_lmbda[1] 1.17 0.86 1.02 -0.21 2.49 67.77 1.04
log_lmbda[2] 1.48 0.81 1.32 0.35 2.95 80.56 1.03
log_lmbda[3] 0.84 0.63 0.79 -0.02 2.06 134.15 1.03
log_lmbda[4] 0.05 1.11 0.15 -1.97 1.65 117.28 1.02
log_lmbda[5] 0.40 0.70 0.32 -0.69 1.59 96.32 1.04
log_lmbda[6] 0.11 1.01 0.16 -1.34 1.93 98.84 1.02
log_lmbda[7] -0.20 1.07 -0.12 -2.26 1.39 92.30 1.05
log_lmbda[8] -1.06 1.24 -0.91 -3.47 0.72 77.22 1.03
log_lmbda[9] -0.02 0.97 -0.10 -1.43 1.79 57.85 1.03
log_lmbda[10] -0.34 1.03 -0.33 -2.12 1.10 132.01 1.02
log_lmbda[11] 0.09 0.83 0.09 -1.15 1.60 82.08 1.03
log_lmbda[12] -0.23 1.09 -0.18 -2.06 1.48 95.83 1.02
log_lmbda[13] -0.91 1.08 -0.92 -2.90 0.69 112.11 1.01
log_lmbda[14] -0.80 1.25 -0.70 -2.80 1.29 84.20 1.02
log_lmbda[15] 0.22 0.95 0.26 -1.20 2.07 40.46 1.09
log_lmbda[16] 0.26 0.75 0.26 -1.19 1.37 118.65 1.01
log_lmbda[17] 0.28 0.86 0.25 -1.21 1.58 109.20 1.02
log_lmbda[18] -0.03 1.12 0.05 -1.86 1.65 33.71 1.08
log_lmbda[19] 0.16 0.98 0.26 -1.48 1.84 77.56 1.04
log_lmbda[20] -0.45 0.96 -0.44 -1.93 1.15 125.66 1.03
log_lmbda[21] -0.98 1.29 -0.76 -3.20 1.12 45.47 1.05
log_lmbda[22] -0.75 1.21 -0.75 -2.61 1.37 63.27 1.05
log_lmbda[23] -1.04 1.21 -1.01 -3.33 0.79 92.31 1.05
log_lmbda[24] -1.13 1.30 -1.05 -3.57 0.79 49.91 1.10
log_tau -1.25 0.35 -1.27 -1.81 -0.65 68.65 1.02
Let’s check if there are any divergent transitions
np.sum(info.is_divergent, axis=1)Array([3, 0, 0, 0], dtype=int32)We warned earlier that the non-centered parametrization was not a one-size-fits-all solution to the funnel geometries that can be present in the posterior distribution. Although there was no divergence, it is still worth checking the posterior interactions between the coefficients to make sure the posterior geometry did not get in the way of sampling:
n_pred = X.shape[-1]
n_col = 4
n_row = (n_pred + n_col - 1) // n_col
_, axes = plt.subplots(n_row, n_col, figsize=(n_col * 3, n_row * 2))
axes = axes.flatten()
for i in range(n_pred):
ax = axes[i]
ax.plot(samples.position["log_lmbda"][...,i],
samples.position["beta"][...,i],
'o', ms=.4, alpha=.75)
ax.set(
xlabel=rf"$\lambda$[{i}]",
ylabel=rf"$\beta$[{i}]",
)
for j in range(i+1, n_col*n_row):
axes[j].remove()
plt.tight_layout();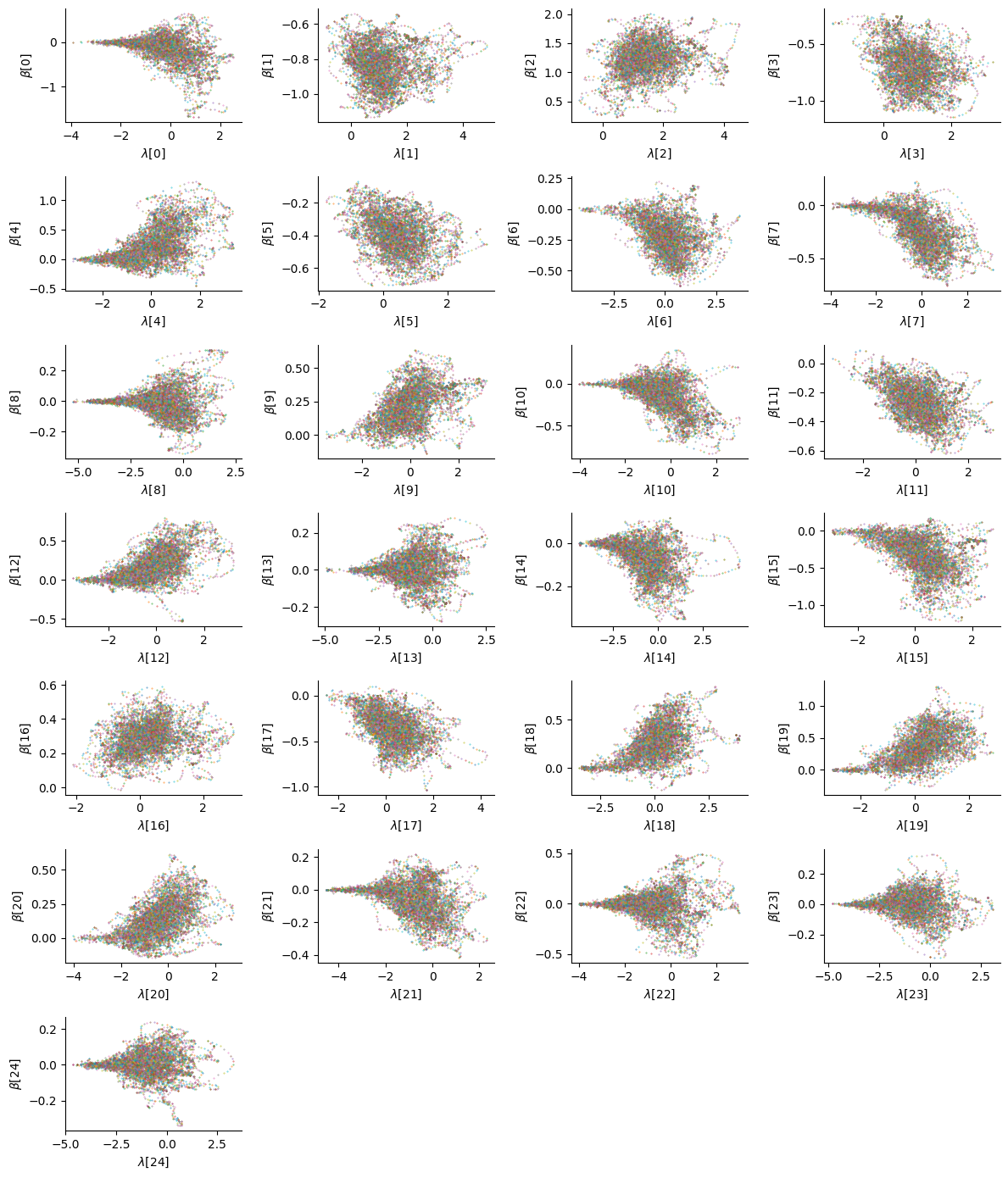
While some parameters (for instance the 15th) exhibit no particular correlations, the funnel geometry can still be observed for a few of them (4th, 13th, etc.). Ideally one would adopt a centered parametrization for those parameters to get a better approximation to the true posterior distribution, but here we also assess the ability of the sampler to explore these funnel geometries.
We can convince ourselves that the Horseshoe prior induces sparsity on the regression coefficients by looking at their posterior distribution:
_, axes = plt.subplots(n_row, n_col, sharex=True, figsize=(n_col * 3, n_row * 2))
axes = axes.flatten()
for i in range(n_pred):
ax = axes[i]
ax.hist(samples.position["beta"][..., i],
bins=50, density=True, histtype="step")
ax.set_xlabel(rf"$\beta$[{i}]")
ax.get_yaxis().set_visible(False)
ax.spines["left"].set_visible(False)
ax.set_xlim([-2, 2])
for j in range(i+1, n_col*n_row):
axes[j].remove()
plt.tight_layout();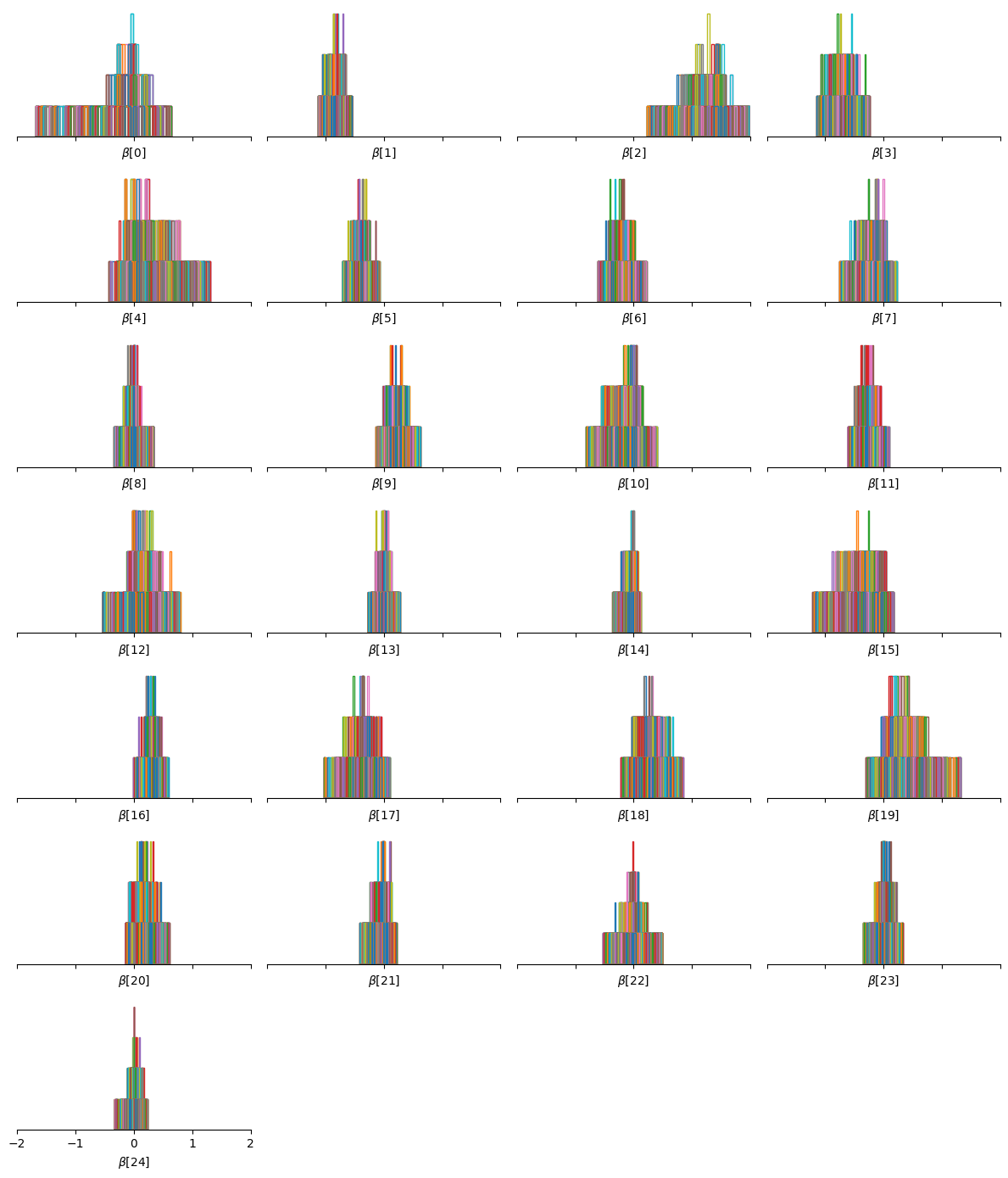
Indeed, many of the parameters are centered around 0.
Bibliography¶
- Carvalho, C. M., Polson, N. G., & Scott, J. G. (2010). The horseshoe estimator for sparse signals. Biometrika, 97(2), 465–480.
- Papaspiliopoulos, O., Roberts, G. O., & Sköld, M. (2007). A general framework for the parametrization of hierarchical models. Statistical Science, 59–73.
- Dua, D., & Graff, C. (2017). UCI Machine Learning Repository. University of California, Irvine, School of Information. http://archive.ics.uci.edu/ml
- Hoffman, M. D., & Sountsov, P. (2022). Tuning-Free Generalized Hamiltonian Monte Carlo. International Conference on Artificial Intelligence and Statistics, 7799–7813.