Pathfinder#
In this notebook we introduce the pathfinder [ZCGV22] algorithm and we show how to use it as a variational inference method or as an initialization tool for MCMC kernels.
import jax
from datetime import date
rng_key = jax.random.key(int(date.today().strftime("%Y%m%d")))
from matplotlib.patches import Ellipse
from sklearn.datasets import make_biclusters
import numpy as np
import jax.numpy as jnp
import blackjax
The Data#
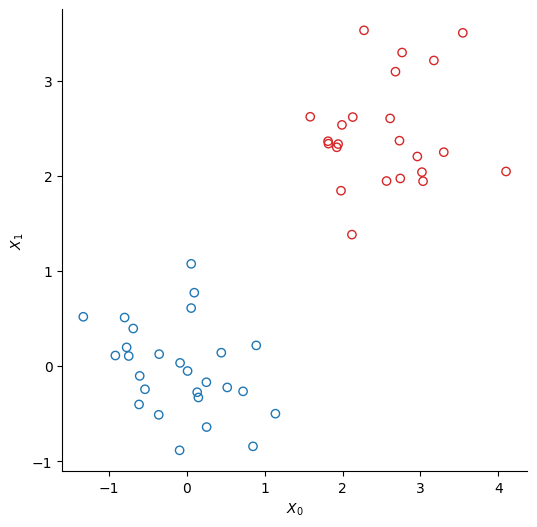
We create two clusters of points using scikit-learn’s make_bicluster function.
num_points = 50
X, rows, cols = make_biclusters(
(num_points, 2), 2, noise=0.6, random_state=314, minval=-3, maxval=3
)
y = rows[0] * 1.0 # y[i] = whether point i belongs to cluster 1
The Model#
We use a simple logistic regression model to infer to which cluster each of the points belongs. We note \(y\) a binary variable that indicates whether a point belongs to the first cluster:
The probability \(p\) to belong to the first cluster commes from a logistic regression:
where \(w\) is a vector of weights whose priors are a normal prior centered on 0:
And \(\Phi\) is the matrix that contains the data, so each row \(\Phi_{i,:}\) is the vector \(\left[X_0^i, X_1^i\right]\)
Phi = X
N, M = Phi.shape
def sigmoid(z):
return jnp.exp(z) / (1 + jnp.exp(z))
def log_sigmoid(z):
return z - jnp.log(1 + jnp.exp(z))
def logdensity_fn(w, alpha=1.0):
"""The log-probability density function of the posterior distribution of the model."""
log_an = log_sigmoid(Phi @ w)
an = Phi @ w
log_likelihood_term = y * log_an + (1 - y) * jnp.log(1 - sigmoid(an))
prior_term = alpha * w @ w / 2
return -prior_term + log_likelihood_term.sum()
Pathfinder: Parallel Quasi-Newton Variational Inference#
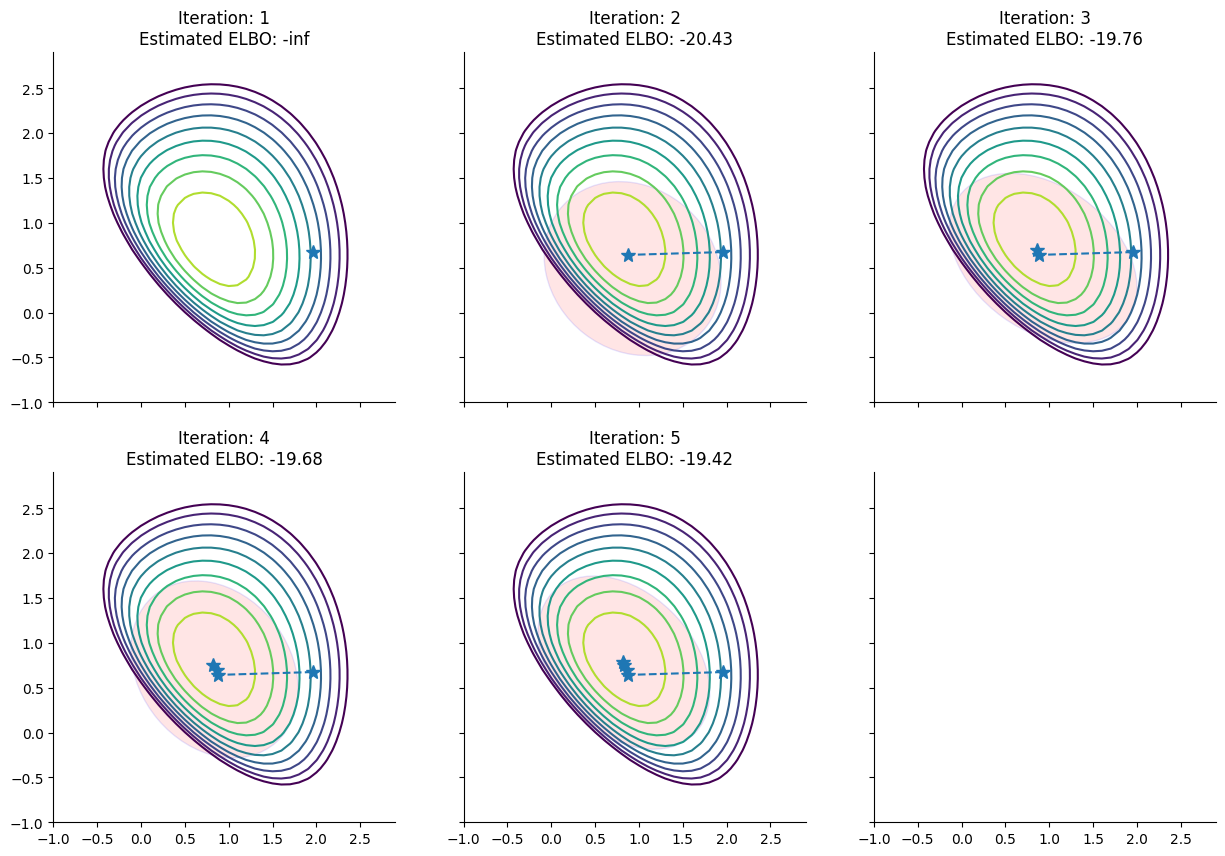
Starting from a random initialization, Pathfinder locates normal approximations to the target density along a quasi-Newton optimization path, with local covariance estimated using the inverse Hessian estimates produced by the optimizer. Pathfinder returns draws from the approximation with the lowest estimated Kullback-Leibler (KL) divergence to the true posterior. The optimizer is the limited memory BFGS algorithm.
To help understand the approximations that pathfinder evaluates during its run, here we plot for each step of the L-BFGS optimizer the approximation of the posterior distribution of the model derived by pathfinder and its ELBO:
# jaxopt lbfgs could fail, hack to keep trying util it works
stop = 0
while stop == 0:
rng_key, init_key, infer_key = jax.random.split(rng_key, 3)
w0 = jax.random.multivariate_normal(init_key, 2.0 + jnp.zeros(M), jnp.eye(M))
_, info = blackjax.vi.pathfinder.approximate(infer_key, logdensity_fn, w0, ftol=1e-6)
path = info.path
stop = np.isfinite(path.elbo).mean()
/tmp/ipykernel_2889/2037720512.py:35: DeprecationWarning: jax.tree_map is deprecated: use jax.tree.map (jax v0.4.25 or newer) or jax.tree_util.tree_map (any JAX version).
state = jax.tree_map(lambda x: x[i], path)
Pathfinder as a Variational Inference Method#
Pathfinder can be used as a variational inference method. We first create a pathfinder object pf which contains two functions approximate and sample:
pf = blackjax.pathfinder(logdensity_fn)
rng_key, approx_key = jax.random.split(rng_key)
state, _ = pf.approximate(approx_key, w0, ftol=1e-4)
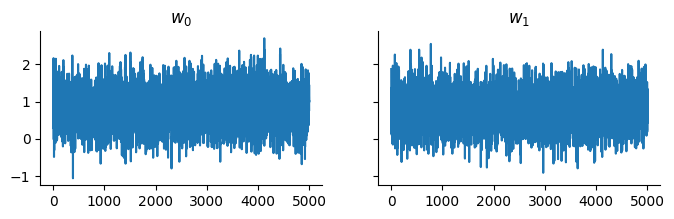
We can now get samples from the approximation:
rng_key, sample_key = jax.random.split(rng_key)
samples, _ = pf.sample(sample_key, state, 5_000)
And display the trace:
Please note that pathfinder is implemented as follows:
it runs L-BFGS optimization and finds the best approximation in the
initphasestepphase it’s just sampling from a multinormal distribution, whose parameters have been already estimated
Hence it makes sense to jit the init function and then use the sample helper function in the pathfinder object instead of implementing the inference loop:
%%time
state, _ = jax.jit(pf.approximate)(approx_key, w0)
samples, _ = pf.sample(sample_key, state, 5_000)
CPU times: user 3 s, sys: 54.8 ms, total: 3.05 s
Wall time: 1.38 s
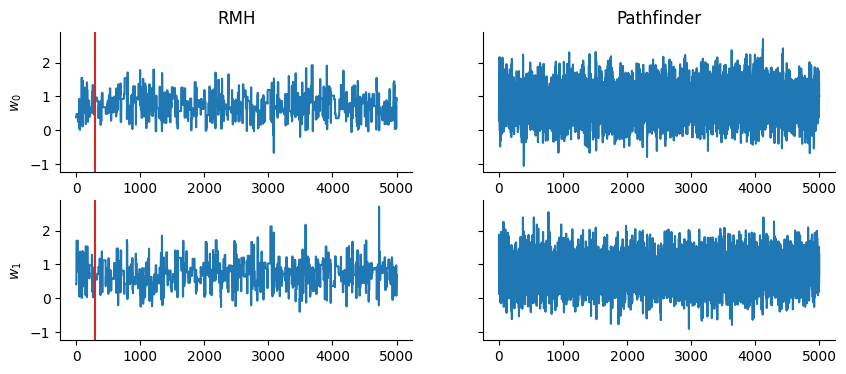
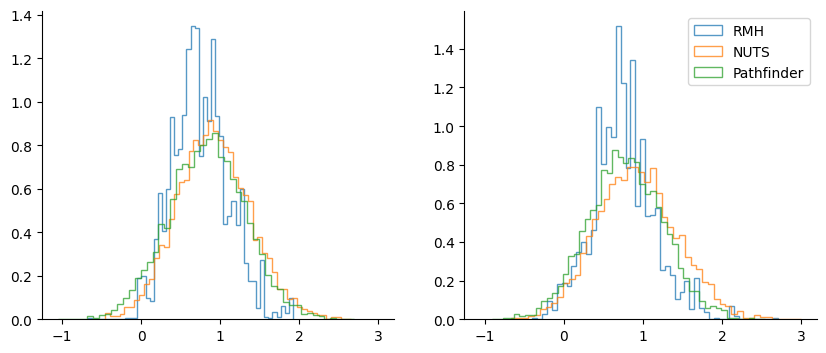
Quick comparison against the Rosenbluth-Metropolis-Hastings kernel rmh:
def inference_loop(rng_key, kernel, initial_state, num_samples):
@jax.jit
def one_step(state, rng_key):
state, info = kernel(rng_key, state)
return state, (state, info)
keys = jax.random.split(rng_key, num_samples)
return jax.lax.scan(one_step, initial_state, keys)
rmh = blackjax.rmh(
logdensity_fn, blackjax.mcmc.random_walk.normal(sigma=jnp.ones(M) * 0.7)
)
state_rmh = rmh.init(w0)
rng_key, sample_key = jax.random.split(rng_key)
_, (samples_rmh, _) = inference_loop(sample_key, rmh.step, state_rmh, 5_000)
Pathfinder as an Initialization Tool for MCMC Kernels#
Pathfinder uses internally the inverse hessian estimation of the L-BFGS optimizer to evaluate the approximations to the target distribution along the quasi-Newton optimization path.
We can calculate explicitly this inverse hessian matrix for a step of the optimization path using the blackjax.optimizers.lbfgs.lbfgs_inverse_hessian_formula_1 function:
from blackjax.optimizers.lbfgs import lbfgs_inverse_hessian_formula_1
inverse_mass_matrix = lbfgs_inverse_hessian_formula_1(
state.alpha, state.beta, state.gamma
)
inverse_mass_matrix
Array([[ 0.23901838, -0.08030263],
[-0.08030259, 0.23023751]], dtype=float32)
This estimation of the inverse mass matrix, coupled with Nesterov’s dual averaging adaptation for estimating the step size, yields an alternative adaptation scheme for initializing MCMC kernels.
This scheme is implemented in blackjax.pathfinder_adaptation function:
adapt = blackjax.pathfinder_adaptation(blackjax.nuts, logdensity_fn)
rng_key, sample_key = jax.random.split(rng_key)
(state, parameters), info = adapt.run(sample_key, w0, 400)
nuts = blackjax.nuts(logdensity_fn, **parameters)
init0 = nuts.init(state.position)
rng_key, sample_key = jax.random.split(rng_key)
_, (samples_nuts, _) = inference_loop(sample_key, nuts.step, init0, 5000)
Some Caveats#
L-BFGS algorithm struggles with float32s and log-likelihood functions; it’s suggested to use double precision numbers. In order to do that in
jaxa configuration variable needs to be set up at initialization time (see here)Otherwise you can stick with float32 mode and try to tweak
ftol,gtol, or the initialization pointIt may make sense to start pathfinder with a “bad” initialization point, in order to make the L-BFGS algorithm run longer and have more datapoints to estimate the inverse hessian matrix.
Lu Zhang, Bob Carpenter, Andrew Gelman, and Aki Vehtari. Pathfinder: parallel quasi-newton variational inference. 2022. arXiv:2108.03782.