Bayesian Logistic Regression With Latent Gaussian Sampler#
In this notebook we reproduce the Logistic Regression example, but by directly leveraging the fact that the prior is Gaussian to use the latent Gaussian model. Most of the code is the same as in the previous notebook, but the sampler (and the adaptation step) will differ.
import jax
from datetime import date
rng_key = jax.random.key(int(date.today().strftime("%Y%m%d")))
import jax.numpy as jnp
from sklearn.datasets import make_biclusters
import blackjax
The data#
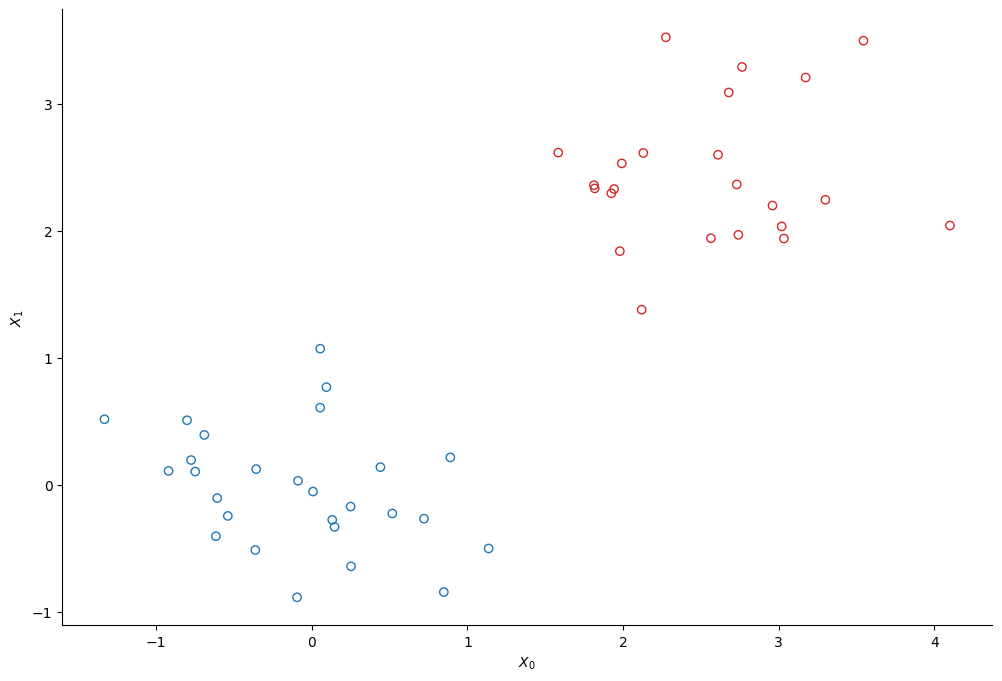
We create two clusters of points using scikit-learn’s make_bicluster function.
num_points = 50
X, rows, cols = make_biclusters(
(num_points, 2), 2, noise=0.6, random_state=314, minval=-3, maxval=3
)
y = rows[0] * 1.0 # y[i] = whether point i belongs to cluster 1
The model#
We use a simple logistic regression model to infer to which cluster each of the points belongs. We note \(y\) a binary variable that indicates whether a point belongs to the first cluster :
The probability \(p\) to belong to the first cluster commes from a logistic regression:
where \(w\) is a vector of weights whose priors are a normal prior centered on 0:
And \(\Phi\) is the matrix that contains the data, so each row \(\Phi_{i,:}\) is the vector \(\left[1, X_0^i, X_1^i\right]\)
Phi = jnp.c_[jnp.ones(num_points)[:, None], X]
N, M = Phi.shape
alpha = 1.0
C = jnp.eye(M) / alpha # covariance of the prior for the weights
def sigmoid(z):
return jnp.exp(z) / (1 + jnp.exp(z))
def log_sigmoid(z):
return z - jnp.log(1 + jnp.exp(z))
def log_likelihood(w):
"""The log-probability density function of the posterior distribution of the model."""
log_an = log_sigmoid(Phi @ w)
an = Phi @ w
log_likelihood_term = y * log_an + (1 - y) * jnp.log(1 - sigmoid(an))
return log_likelihood_term.sum()
Posterior sampling#
We use blackjax’s Latent Gaussian sampler to sample from the posterior distribution.
from blackjax.mcmc.marginal_latent_gaussian import (
init,
build_kernel,
svd_from_covariance,
)
cov_svd = svd_from_covariance(C)
U, Gamma, U_t = cov_svd
w0 = jnp.zeros((M,))
init_fn = lambda x: init(x, log_likelihood, U_t)
initial_state = init_fn(w0)
kernel = build_kernel(cov_svd)
step = lambda k, x, delta: kernel(k, x, log_likelihood, delta)
We first define a calibration loop. The goal is to find the “step-size” delta that approximately corresponds to an acceptance probability of 0.5.
def calibration_loop(
rng_key,
initial_state,
initial_delta,
num_steps,
update_every=100,
target=0.5,
rate=0.5,
):
def body(carry):
i, state, delta, pct_accepted, rng_key = carry
rng_key, rng_key2 = jax.random.split(rng_key, 2)
state, info = step(rng_key, state, delta)
# restart calibration of delta
j = i % update_every
pct_accepted = (j * pct_accepted + info.is_accepted) / (j + 1)
diff = target - pct_accepted
delta = jax.lax.cond(
j == 0, lambda _: delta * (1 - diff * rate), lambda _: delta, None
)
return i + 1, state, delta, pct_accepted, rng_key2
_, final_state, final_delta, final_pct_accepted, _ = jax.lax.while_loop(
lambda carry: carry[0] < num_steps,
body,
(0, initial_state, initial_delta, 0.0, rng_key),
)
return final_state, final_delta
def inference_loop(rng_key, initial_delta, initial_state, num_samples, num_burnin):
rng_key, rng_key2 = jax.random.split(rng_key, 2)
initial_state, delta = calibration_loop(
rng_key, initial_state, initial_delta, num_burnin
)
@jax.jit
def one_step(carry, rng_key):
i, pct_accepted, state = carry
state, info = step(rng_key, state, delta)
pct_accepted = (i * pct_accepted + info.is_accepted) / (i + 1)
return (i + 1, pct_accepted, state), state
keys = jax.random.split(rng_key, num_samples)
(_, tota_pct_accepted, _), states = jax.lax.scan(
one_step, (0, 0.0, initial_state), keys
)
return states, tota_pct_accepted
We can now run the inference:
rng_key, sample_key = jax.random.split(rng_key)
states, tota_pct_accepted = inference_loop(sample_key, 0.5, initial_state, 5_000, 1_000)
print(f"Percentage of accepted samples (after calibration): {tota_pct_accepted:.2%}")
Percentage of accepted samples (after calibration): 77.22%
And display the trace:
chains = states.position
nsamp, _ = chains.shape
Predictive distribution#
Having infered the posterior distribution of the regression’s coefficients we can compute the probability to belong to the first cluster at each position \((X_0, X_1)\).
# Create a meshgrid
xmin, ymin = X.min(axis=0) - 0.1
xmax, ymax = X.max(axis=0) + 0.1
step = 0.1
Xspace = jnp.mgrid[xmin:xmax:step, ymin:ymax:step]
_, nx, ny = Xspace.shape
# Compute the average probability to belong to the first cluster at each point on the meshgrid
Phispace = jnp.concatenate([jnp.ones((1, nx, ny)), Xspace])
Z_mcmc = sigmoid(jnp.einsum("mij,sm->sij", Phispace, chains))
Z_mcmc = Z_mcmc.mean(axis=0)
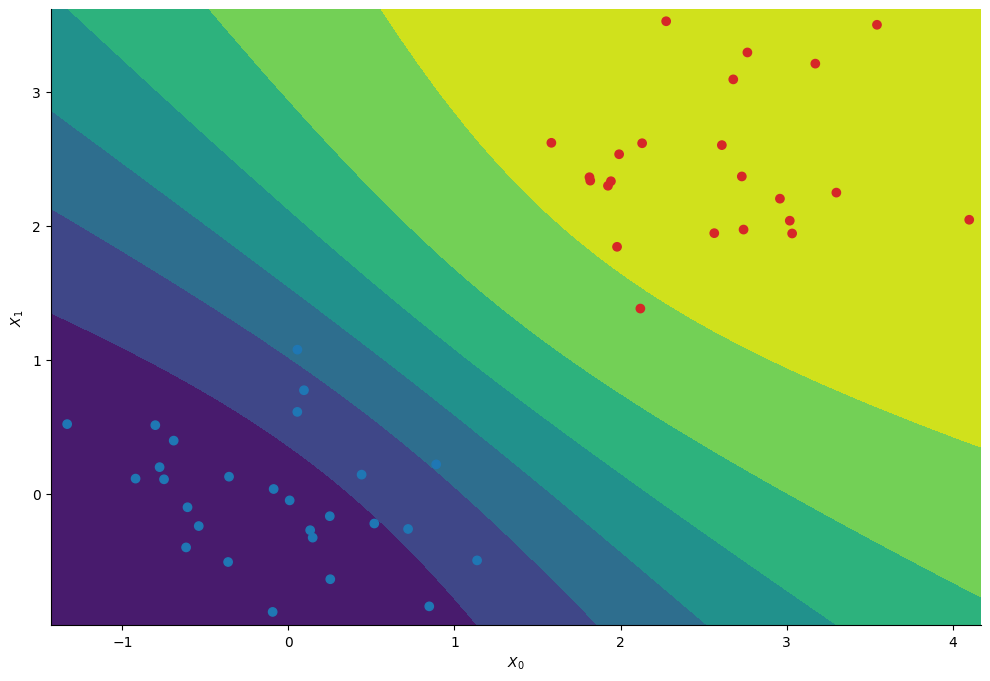
We essentially recover the same contours as with the standard random walk approach.